🚀 QEMU Live Migrations: Post-Copy and Auto-Converge features
 Photo by Barth Bailey on Unsplash
Photo by Barth Bailey on Unsplash
Cloud lifecycle is a complex process that involves several procedures such as maintenance and upgrades. These operations mostly include migration of workloads. OpenStack provides several options to perform such moving:
- Cold migration
- Live migrations
- Instance rebuilds
From the list above only live migration allows moving an instance from one host to another with almost *zero downtime, which is done seamlessly for the instance itself.
In one of our previous researches we’ve noticed that, by default, QEMU/KVM live migration has a pretty low convergence for heavy-loaded virtual machines. The convergence property reflects the ratio or difference between VM memory transfer speed and VM memory dirty speed during the live migration, if the memory transfer speed is higher or insignificantly lower, then live migration succeeds.
In this post, we’re going to analyze different QEMU features that may help live migrations converge. The most important features are Post-Copy and Auto-Converge.
Auto-Converge (AC). The idea behind auto-converge is pretty simple — by throttling down the virtual CPU execution time, the guest machine is prevented from dirtying memory faster than memory can be transferred over the wire. By default, QEMU throttles vCPU by 20% and increases the throttling rate by 10% each iteration. This guarantees the that guest machine eventually migrates.
Post-Copy (PC). The goal of post-copy is to transfer some portion of memory in normal pre-copy mode, then switch the guest to the destination node and request any missing memory pages on demand. This comes with the additional cost of waiting for a particular page to transfer from the source node, however, post-copy guarantees that guest migrates in a constant amount of time. The downside of using post-copy is that if the destination node fails or there is a network interruption, it becomes impossible to recover the guest machine state as it is distributed between the source and destination nodes.
We wanted to answer the following questions:
- How do various parameters of the post-copy and auto-converge features affect the migration outcome?
- Does the migration
max_downtimeparameter have any impact on migration success?
Test Harness
Test Environment
Our setup consists of two hypervisor nodes, one monitoring VM and workstation. The monitoring VM runs on a separate machine. Tests are executed from a workstation which is connected to the same network as monitoring VM and hypervisor machines.
All servers have the same configuration:
| Parameter | Description |
|---|---|
| CPU | 1x CPU Intel Xeon E3-1230, 3.20GHz, Socket 1155, 8MB Cache, 4 core, 80W |
| RAM | 4x RAM 4GB Kingston KVR1333D3E9S/4GHB, DDR-III PC3-10600 |
| Hard drive | 2x HDD 1.5 TB, WD Caviar Black, WD1502FAEX, SATA 6.0 Gb/s, 7200 RPM, 64MB, 3.5” |
| Network | 1x NIC AOC-CGP-i2, PCI-E x4, 2-port Gigabit Ethernet LAN |
Software versions:
- Operating system: Ubuntu 16.04 LTS
- QEMU version: 2.6.0
- Libvirt version: 1.3.5
Tools
The test suite consists of 3 main parts:
- Orchestration - Orchestra
- Metrics storage - Influxdb
- Monitoring agents, - Telegraf and migration monitor.
- Stress tool for dirtying the VM memory (example of cmdline parameters:
--vm 1 --vm-bytes 128M. Number of workers and amount of memory per each).
Orchestra is responsible for managing instances during scenario run (boot, live-migrate, etc.), and also enabling/disabling monitoring. Ansible playbooks are used for update-config/setup up monitoring on hypervisor nodes or booted instances.
Influxdb is a time series database that is used for storing events from host hypervisors/instances. Migration monitor - a special tool that allows capturing events from libvirt to measure live-migration time, timeouts, and dirty pages rate.
Test scenarios
The first set of scenarios is aimed to explore how different settings of auto-converge parameters affect the migration duration and outcome. For all tests, we’ve used guest machines with 1 vCPU and 2Gb of RAM. As a baseline for the load, we’ve used 2 memory workers dirtying constantly 512Mb each, such load is sufficient to make default live migration last forever.
Parameters definitions
--auto-converge: Enables auto-converge feature. The initial guest CPU throttling rate can be set withauto-converge-initial(orx-cpu-throttle-initial). If the initial throttling rate is not enough to ensure convergence, the rate is periodically increased byauto-converge-increment(x-cpu-throttle-increment).x-cpu-throttle-initialandx-cpu-throttle-increment: QEMU migration parameters specified via monitor command:virsh qemu-monitor-command <domain_name> --hmp --cmd "migration_set_parameter x-cpu-throttle-initial 50". According to Features/AutoconvergeLiveMigration, the initial throttling percentage defaults to 20%. If after a period of time the migration has still not completed then throttling is incremented. This process continues until migration completes or we reach 99% throttled. By default the throttling rate is always incremented by 10%.--postcopy: enables post-copy logic in migration, but does not actually start post-copy.--postcopy-after-precopy: let libvirt automatically switch to post-copy after the first pass of pre-copy is finished.--compressed: activates compression, the compression method is chosen with –comp-methods. Supported methods are “mt” and “xbzrle” and can be used in any combination. When no methods are specified, a hypervisor default methods will be used. QEMU defaults to “xbzrle”.--timeout-postcopy: When –timeout-postcopy is used, virsh will switch migration from pre-copy to post-copy upon timeout.migrate-setmaxdowntime: Set maximum tolerable downtime for a domain which is being live-migrated to another host. The downtime is a number of milliseconds the guest is allowed to be down at the end of live migration.
| # | Load | Auto-Converge params |
|---|---|---|
| 1. | 2 workers, 512Mb mem allocated | --auto-convergex-cpu-throttle-initial 20x-cpu-throttle-increment 10default settings, see migration.c |
| 2. | same | --auto-convergex-cpu-throttle-initial 30x-cpu-throttle-increment 15 |
| 3. | same | --auto-convergex-cpu-throttle-initial 50x-cpu-throttle-increment 20 |
Next part is to investigate post-copy related parameters.
The difference between scenarios 4 and 5 is that by default QEMU uses pre-copy, and post-copy should be either triggered explicitly during the migration or internally by timeout. Flag --postcopy-after-precopy indicates that post-copy step will be triggered after the first iteration of pre-copy. Flag --timeout-postcopy indicates that post-copy step will be automatically triggered after a timeout.
| # | Load | Post-Copy params |
|---|---|---|
| 4. | 2 workers, 512Mb mem allocated | --auto-converge--timeout-postcopy--timeout 60 |
| 5. | same | --postcopy--postcopy-after-precopy |
| 6. | same | --postcopy--postcopy-after-precopy--compressed |
Next two scenarios define more aggressive load and aim to test both auto-converge and post-copy migrations under that load pattern.
| # | Load | Auto-Converge/Post-Copy params |
|---|---|---|
| 7. | 3 workers, 512Mb mem allocated | --auto-convergex-cpu-throttle-initial 50x-cpu-throttle-increment 20 |
| 8. | same | --postcopy--postcopy-after-precopy |
Finally, we’re going to test how migration max_downtime parameter affects the live migration duration.
| # | Load | Post-Copy params |
|---|---|---|
| 9. | 3 workers, 512Mb mem allocated | --auto-convergedefault settings |
| 10. | same | --auto-convergemigrate-setmaxdowntime 1000 |
| 11. | same | --auto-convergemigrate-setmaxdowntime 5000 |
Test Results
Graphical examples of the Live migration with default auto-converge, customized auto-converge and default post-copy modes. Each figure has three graphs: migration duration, mem dirtying rate, and remaining memory dynamics. Each figure shows 5 min timeframe to make it easier to reason about migration duration. Load pattern is the same: 2 workers with 512Mb allocated for dirtying.
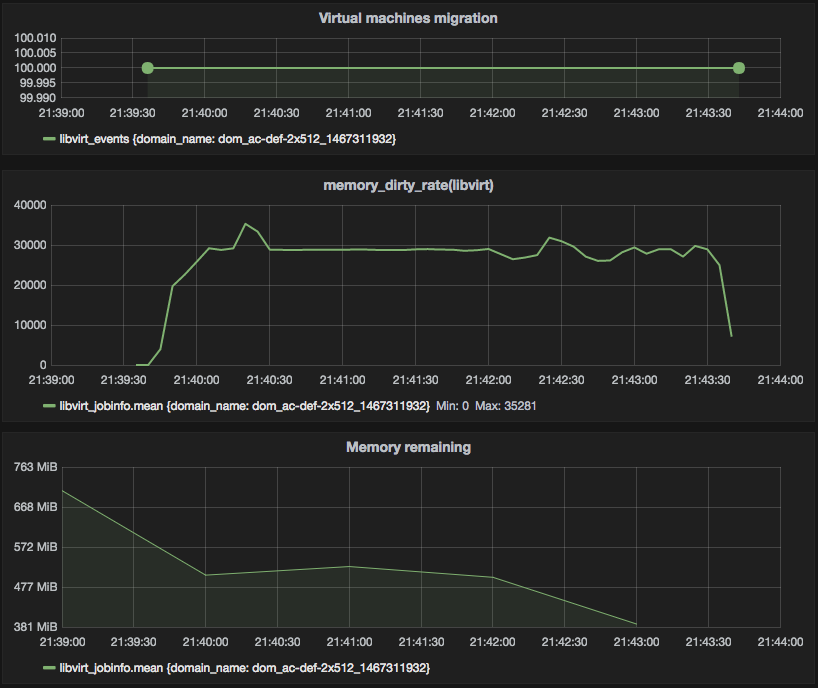 Figure 1 — default auto-converge
Figure 1 — default auto-converge
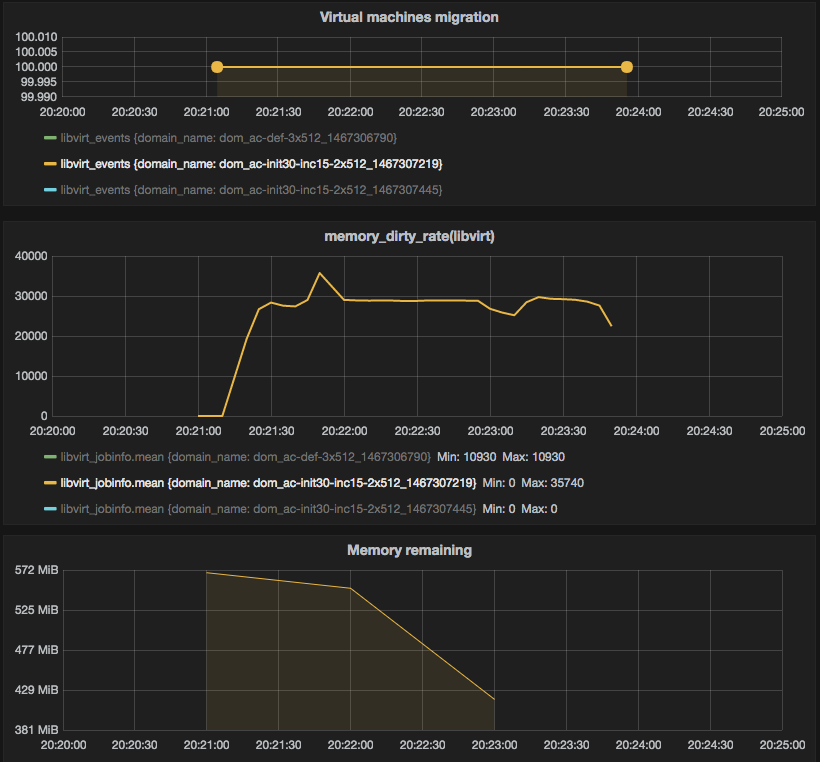 Figure 2 — customized auto-converge (initial: 30%, increment: 15%)
Figure 2 — customized auto-converge (initial: 30%, increment: 15%)
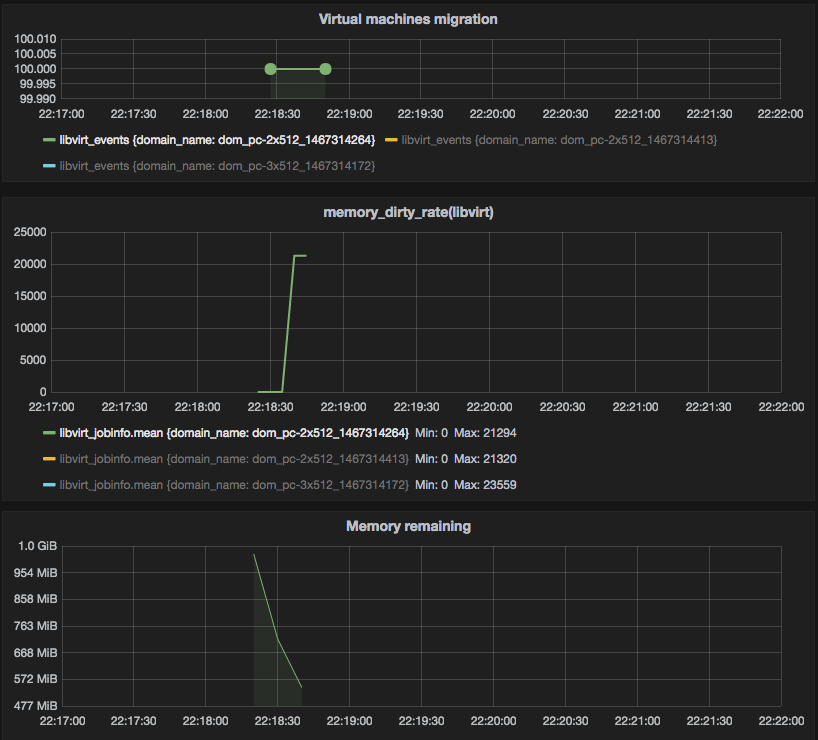 Figure 3 — post-copy
Figure 3 — post-copy
Test results for the first two sets of scenarios (auto-converge and post-copy with baseline load config):
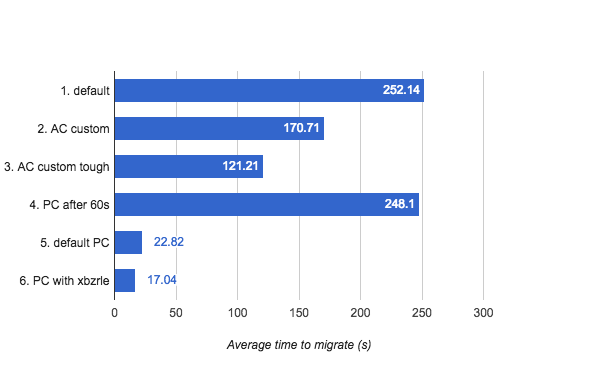 Figure 4 — auto-converge and post-copy comparison chart
Figure 4 — auto-converge and post-copy comparison chart
First three scenarios look pretty reasonable: QEMU with default settings for auto-converge migrates machine in 252 seconds, with more tough custom parameters migration time decreases. Scenario #4 showed slightly better results rather than #1 which requires some additional investigation, as QEMU should turn on post-copy (which we see in #5 and #6 is much faster compared to auto-converge) after 60 seconds.
Success rate for all scenarios except #6 is 100% :
| Scenario | Success Rate |
|---|---|
| 1. default | 100% |
| 2. AC custom | 100% |
| 3. AC custom tough | 100% |
| 4. PC after 60s | 100% |
| 5. default PC | 100% |
| 6. PC with xbzrle | 40% |
With increased load (3 workers, 512Mb allocated) situation is pretty the same for auto-converge and post-copy: auto-converge is much slower than post-copy.
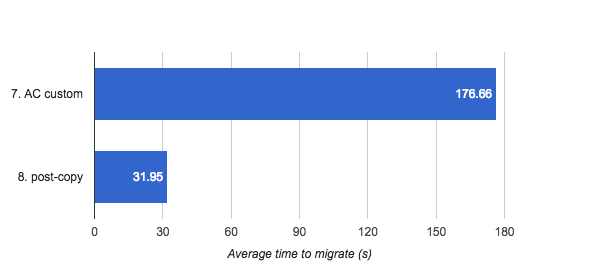 Figure 5 — auto-converge and post-copy comparison chart for increased load
Figure 5 — auto-converge and post-copy comparison chart for increased load
The final part is the comparison of different settings for the max_downtime parameter. Greater max_downtime you have, less time to migrate you need.
Each figure shows 7 min timeframe. Default max_downtime value for QEMU is 300(ms), according to QEMU source code (2.6.0 release branch).
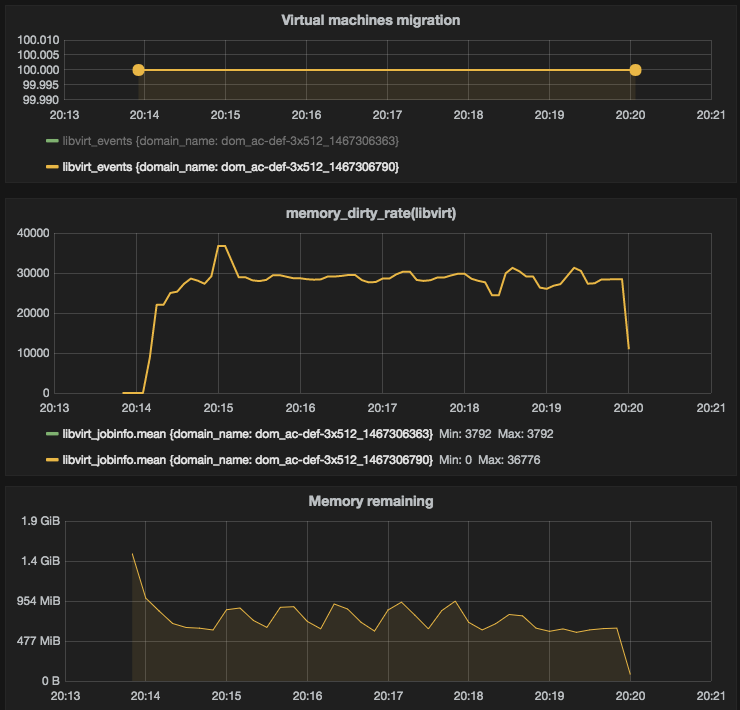 Figure 6 — Auto-converge with default
Figure 6 — Auto-converge with default max_downtime settings
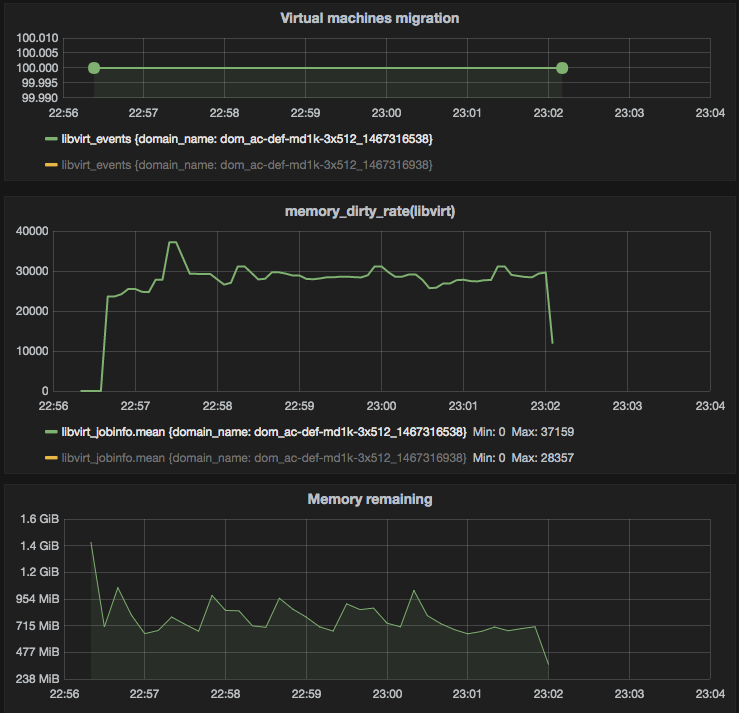 Figure 7 — Auto-converge with
Figure 7 — Auto-converge with max_downtime set to 1000 (ms)
This is a less realistic scenario (max_downtime = 5000ms), it is shown just to compare it with 1000ms and 300ms. A better option is to use OpenStack Nova force_complete feature that allows heavy loaded machines that cannot be live-migrated to be paused during the migration.
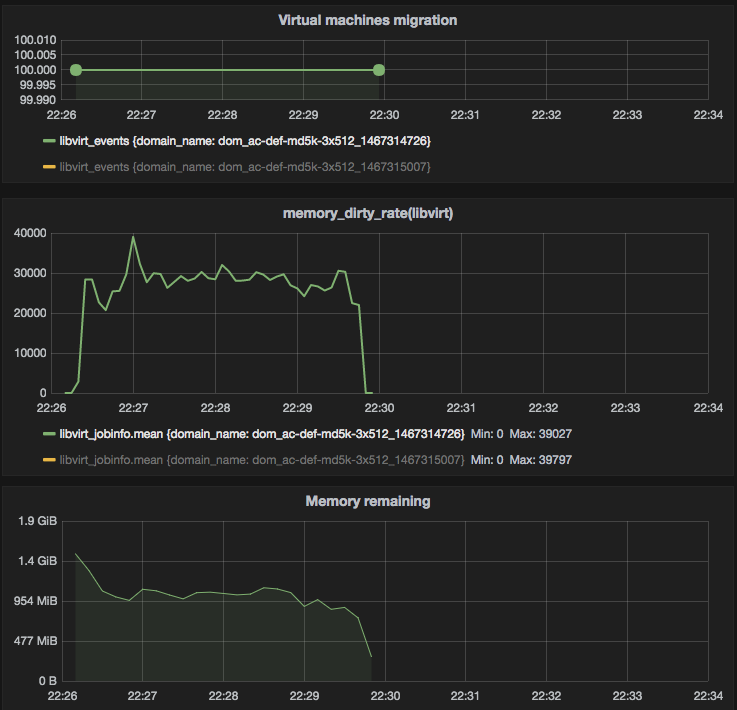 Figure 8 — Auto-converge with
Figure 8 — Auto-converge with max_downtime set to 5000 (ms)
And summary chart looks like this:
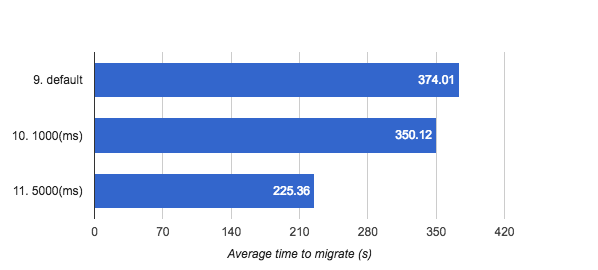 Figure 9 — auto-converge with different
Figure 9 — auto-converge with different max_downtime settings
Conclusions
Our aim was a comparison of different live migration techniques under various configuration parameters, in order to demonstrate and recommend an appropriate usage of post-copy and auto-converge.
From the results above, we see that post-copy performs much better than other techniques, except when compression is used simultaneously. It’s actually not quite true, because during the post-copy phase VM performance degrades significantly, which was not measured.
Both, auto-converge and post-copy, perform very well. Live migration in a post-copy mode can finish in a finite time. However, memory of a VM is spread between source and destination node, so in case of any failure there is a risk that the VM will need to be rebooted on destination. There is no such risk when using auto-converge, but it does not guarantee that live migration will end. Something that still needs a research is how post-copy impacts workload running on a VM and a comparison of that with how auto-converge impacts the workload.
References
The following materials were used:
- “Dive Into VM Live Migration” https://01.org/sites/default/files/dive_into_vm_live_migration_2.pdf
- “Analysis of techniques for ensuring migration completion with KVM” https://www.berrange.com/posts/2016/05/12/analysis-of-techniques-for-ensuring-migration-completion-with-kvm/